
Poco’s AI NOTE 前回の記事でBrowser Use CLI 2.0のセットアップが完了したので、今回は「本当に入れる意味あるの?」を実際に測って検証します。

検証の目的
Browser Use CLI 2.0は「従来比で2倍速い」と宣伝しています(旧バージョンのPlaywright経由→CDP直接通信への改善による速度向上)。
でもそもそもの疑問として、Claude Codeって元々curlやweb_fetchでWebページの情報を取れますよね。 わざわざBrowser Use CLIを入れる意味あるの?
これを実際に同じタスクで計測して、データで答えを出します。
検証方法
検証環境
- Windows 11
- Claude Code v2.1.80(Opus 4.6 / Claude Max)
- Browser Use CLI 0.12.2(Python 3.12.9)
- 計測日:2026年3月20日
比較パターン
- 「あり」:Claude Code + browser-use Skill(ブラウザ操作可能)
- 「なし」:Claude Code 単体(browser-use Skillを無効化)
同じ指示文を出して、答えが返ってくるまでの時間をストップウォッチで計測しました。
※ 各タスク1回ずつの計測です。厳密な統計データではなく、体感ベースの参考値としてご覧ください。LLMの応答にはばらつきがあるため、毎回同じ結果にはなりません。
「なし」の状態を作るのは簡単で、browser-useのSkillファイル(SKILL.md)のファイル名を一時的に変えるだけ。Claude Codeは起動時にこのファイルを探しに行くので、名前が違うと「browser-use?知らないなぁ」となります。
3つのタスクで計測
難易度を3段階に分けました。
| タスク | 内容 | 難しさ |
|---|---|---|
| タスク1 | Hacker Newsのトップ10記事を取得 | ★☆☆ |
| タスク2 | 書籍サイトから一覧を取得 | ★★☆ |
| タスク3 | ボタンを押した後に表示されるテキストを取得 | ★★★ |
結果
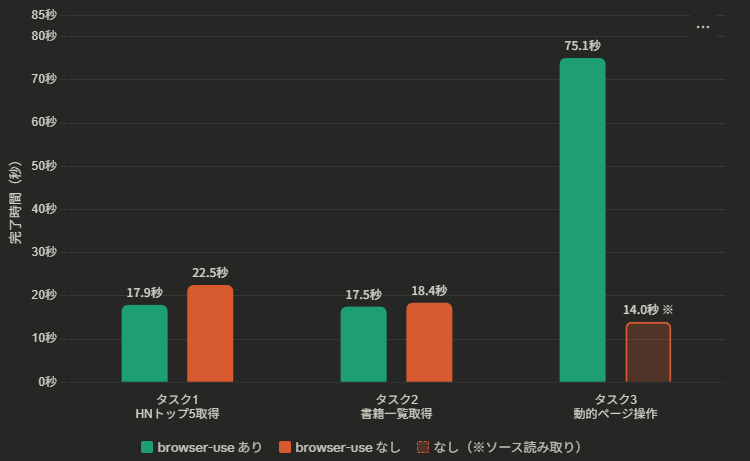
「あり」は実際にボタンをクリックして表示を待ち、正規の方法で取得。
※グラフ中タスク1では「HNトップ5」とありますが、実際の計測はトップ10で実施しています
タスク1:Hacker Newsトップ10記事の取得
指示文: 「Hacker Newsのトップ10記事のタイトルとURLを取得して、一覧にして」
| 時間 | 結果 | |
|---|---|---|
| あり | 17.9秒 | 成功 |
| なし | 22.5秒 | 成功 |
差:4.6秒(あり の方が約20%速い)
どちらも成功。「なし」の方はcurlコマンドやHTMLのパースを何度か試行錯誤していて、その分時間がかかりました。「あり」はbrowser-useでページを開いて要素を取得する、というシンプルな流れ。
ただ、正直この程度の差なら「なしでもいいか」と思えるレベルです。
タスク2:書籍サイトから一覧取得
指示文: 「https://books.toscrape.com の「Travel」カテゴリにある本のタイトルと価格を全部取得して一覧にして」
books.toscrape.comはスクレイピング練習用の公開サイトです
| 時間 | 結果 | |
|---|---|---|
| あり | 17.5秒 | 成功 |
| なし | 18.4秒 | 成功 |
差:0.9秒(ほぼ同じ)
ほぼ差なし。このタスクはHTMLの構造がシンプルなので、curlでHTMLを取得→パースする方法でも十分対応できた結果です。
ここまでの2つだと、「別にbrowser-useなくてもよくない?」という感想になりますよね。
タスク3:動的ページのボタン操作
ここが今回の検証のハイライトです。
指示文: 「https://the-internet.herokuapp.com/dynamic_loading/1 にアクセスして、「Start」ボタンを押した後に表示されるテキストを教えて」
このページは「Start」ボタンをクリックすると、ローディングアニメーションが約5秒間表示され、その後に隠されていたテキストが出現する、というテスト用ページです。
| 時間 | 結果 | |
|---|---|---|
| あり | 75.1秒 | 成功(正規の方法で) |
| なし | 14.0秒 | ⚠️ 正解はしたが… |
数字だけ見ると「なしの方が圧倒的に速いじゃん!」と思いますよね。
でも、中身が全然違います。
タスク3の「なし」をよく見ると
「なし」のClaude Codeは、web_fetchでこのページのHTMLソースコードを丸ごと取得しました。 そしてHTMLの中を解析して、こう報告しています:
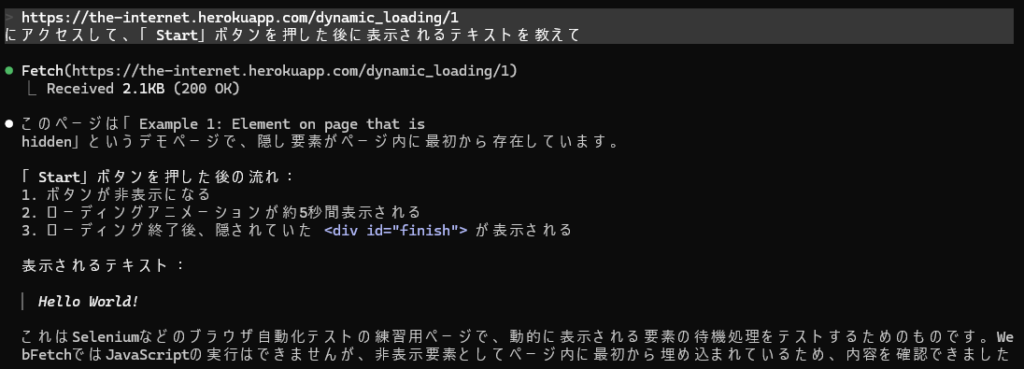
「このページには非表示要素として
<div id="finish">がページ内に最初から埋め込まれているため、内容を確認できました」
つまり、ボタンは一切押していません。
HTMLのソースコードに「隠し要素」として答えが書いてあったのを見つけて、それを読み上げただけ。確かに答え自体は合っています。でもこれは「ボタンを押した後に表示されるテキストを教えて」という指示に対する正しい回答でしょうか?
現実のWebアプリやサービスでは、ボタンを押した後の表示内容がHTMLに最初から埋まっていることはほとんどありません。サーバーに問い合わせて初めて返ってくるデータが大半です。今回はテスト用サイトだからたまたま推測できたけど、実際の業務では通用しない方法です。
一方「あり」の方は:
- browser-useでページにアクセス
- 「Start」ボタンを発見してクリック
- ローディングアニメーションを待機
- 表示されたテキストを取得
指示通り、ボタンを押して、表示されたテキストを取得しています。
75秒かかったのは、ブラウザの起動・ページ読み込み・ローディング待機を含むため。時間はかかったけど、やっていることは「正しい」。
この検証でわかったこと
速さだけの問題じゃない
タスク1や2のような「情報を取ってくるだけ」のタスクでは、browser-useの有無で大きな差は出ませんでした。Claude Code単体でもcurlやweb_fetchで十分対応できます。
でもタスク3で明らかになったのは、「できることの質」が違うということです。
browser-useがあるClaude Codeは:
- ボタンをクリックできる
- ローディングを待てる
- JavaScriptで動的に変わるページに対応できる
- つまり「人間がブラウザでやる操作」を再現できる
browser-useがないClaude Codeは:
- HTMLのソースコードを読むことしかできない
- ボタンを押すことはできない
- JavaScriptの実行結果を見ることはできない
- 静的なHTMLの解析で「推測」するしかない
browser-useを入れるべき人
- ログインが必要なサイトを自動操作したい
- フォーム入力や送信を自動化したい
- JavaScriptで動的に表示される情報を取得したい
- 「人間の代わりにブラウザ作業をやってほしい」がゴール
入れなくてもいい人
- 公開されているWebページの情報を取るだけ
- HTMLの構造がシンプルなサイトが対象
- APIが使える場合(APIの方が速くて正確)
まとめ
| 観点 | browser-use あり | なし |
|---|---|---|
| 静的ページの情報取得 | 少し速い(〜20%) | 十分対応可能 |
| 動的ページの操作 | 正規の方法で対応 | ソース読みで推測 |
| ボタン・フォーム操作 | 可能 | 不可能 |
| ログイン済みサイト | 可能 | 不可能 |
| セットアップの手間 | あり(前回の記事参照) | なし |
結論:速さの差は小さいけど、「できることの幅」が圧倒的に違う。
ただ、タスクを大量に任せる人は、チリツモで時間の節約に大きく貢献すると思います。
特にタスク3のように「ボタンを押さないと見えない情報」は、browser-useなしでは正攻法で取得できません。今回はたまたまHTMLに答えが埋まっていたから推測できたけど、いつもそうとは限らない。
AIに「ブラウザを操作する手」を与えるかどうか。
それがBrowser Use CLIを入れるかどうかの判断基準です。
関連記事
Browser Use CLI 2.0のインストール手順はこちら:


コメント